4.2空间信息分类
空间信息分类方法是地理信息系统功能组成的重要组成部分。与地图相比较,地图上所载负的数据是经过专门分类和处理过的;而地理信息系统存储的数据则具有原始数据的性质,这样用户就可以根据不同的使用目的对数据进行任意提取和分析。对于数据分析来说,随着采用的分类方法和插值方法的不同,得到的结果会有很大的差异。因此,在大多数情况下,首先是将大量未经分类的数据输入地理信息系统的数据库,然后根据用户建立的具体分类算法来获得所需要的信息。以下介绍空间信息分类中常用的几种数学方法。
(一)主成分分析法
地理问题往往涉及大量相互关联的自然和社会要素。众多的要素常常给分析带来很大困难,同时也增加了运算的复杂性。主成分分析法通过数理统计分析,将众多要素的信息压缩表达为若干具有代表性的合成变量,这就克服了变量选择时的冗余和相关,然后选择信息最丰富的少数因子进行各种聚类分析。
设有m个样本,n个变量,构造矩阵
Z=(Xij)nXm
![]()
其斜方差方阵R为实对称矩阵,用Jacobi方法找出线性变换
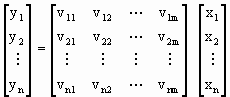
使得y1,y2,…,yn线性无关。R矩阵的特征值越大,该主成分的贡献越大,因而可以选择累计贡献百分率在一定阈值以内的若干因子作为主因子参加分析运算。
(二)层次分析法(AHP)
在分析涉及大量相互关联、相互制约的复杂因素时,各因素对问题的分析有着不同程度的重要性,决定它们对目标的重要性序列对问题的分析十分重要。AHP方法把相互关联的要素按隶属关系划分为若干层次,请有经验的专家们对各层次各因素的相对重要性给出定量指标,利用数学方法,综合众人意见给出各层次各要素的相对重要性权值,作为综合分析的基础。
(三)系统聚类分析
系统聚类是根据多种地学要素对地理实体划分类别的方法。对不同的要素划分类别往往反映不同对象的等级序列,如土地分等定级、水土流失强度分级等。
系统聚类根据实体间的相似程度,逐步合并为若干类别,其相似程度由距离或相似系数定义,主要有绝对值距离、欧氏距离、切比雪夫距离、马氏距离等。
(四)判别分析
判别分析与聚类分析同属分类问题。所不同的是,判别分析是根据理论与实践,预先确定出等级序列的因子标准,再将分析的地理实体安排到序列的合理位置上。对于诸如水土流失评价、土地适宜性评价等有一定理论根据的分类系统的定级问题比较适用。常规的判别分析主要有距离判别法和Bayes最小风险判别法等。