我们知道,海量数据可以泛指巨量的事务性数据,也可专指巨量的空间数据。对于巨量的事务性数据的处理,目前已有非常成熟的数据库技术,可采用分布式的数据库(面向对象的或关系的)来处理这些海量信息。对于巨量的空间数据,由于其自身的特点,目前的基于结构化的数据库技术还不能很好地独立处理这类海量信息。
要处理海量空间信息,在数据处理的过程中必须遵守以下原则:
(1)共享原则。空间信息的共享可以使数据具有更大的应用前景。
(2)数据独立性原则,即要处理的数据与应用程序之间是分离的。这使得同样的数据可以被不同的应用程序利用。
(3)最小冗余度原则。
(4)统一管理原则,即将巨量的数据统一管理,而不管数据具体的存放地址。
由于空间数据种类很多,所以目前通用的空间数据模型有以下几类:
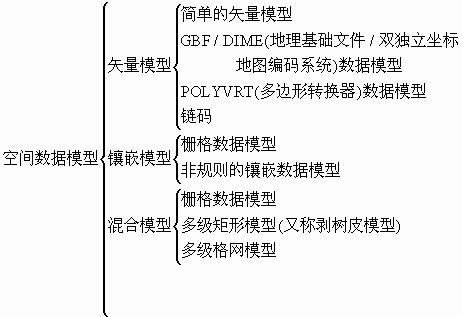
在空间数据模型上,以往的GIS系统都是将几何意义上的空间数据和其对应的属性数据分开存储,属性数据用数据库管理,空间数据用文件管理。上面提到的空间数据模型均是如此,它们在空间数据索引上通常采用四叉树、八叉树、B-树等方法。
为了解决这个问题,目前研究的热点集中在面向对象的数据模型和空间数据仓库技术。面向对象的数据模型是采用面向对象技术建立数据模型,具有封装、继承等特点。它可以将几何数据和属性数据置于一个逻辑上统一的面向对象的数据模型之中。
而空间数据仓库技术则是真正意义上的用数据库来管理海量的空间数据。由于空间数据具有非结构性特点,因此,在此技术的研究和探索上还有很长的路要走。要着重解决多维数据存储、数据共享、数据一致性、数据采集和挖掘及系统性能等诸多问题。