区域型物体的四叉树表示方法最早出现在加拿大地理信息系统CGIS中。80年代以来,四叉树编码在图象分割、数据压缩、地理信息系统等方面进行了大量研究,对四叉树数据结构提出了许多编码方案。
一、常规四叉树
四叉树分割的基本思想是首先把一幅图象或一幅栅格地图(2n×2n,n>1)等分成4部分,逐块检查其栅格值,若每个子区中所有栅格都含有相同值,则该子区不再往下分割,否则,将该区域再分割成4个子区域,如此递归地分割,直到每个子块都含有相同的灰度或属性值为止。这样的数据组织称为自上往下(Top-to-Down)的常规四叉树。四叉树也可自下而上(Down-to-Top)的建立。这时,从底层开始对每个栅格数据的值进行检测,对具有相同灰度或属性的四等分的子区进行合并,如此递归向上合并。

图3-14表示了四叉树的分解过程。图中对23×23的栅格图,利用自上而下方法表示了寻找栅格A的过程。
从四叉树的特点可知,一幅2N×2N栅格阵列图,具有的最大深度数为N,可能具有的层次为0,1,2,3,……N。
每层的栅格宽度,即为每层边长上包含的最大栅格数,反映了所在叶结点表示的正方形集合的大小。其值为:
2(最大深度-当前层次)
例如:一幅23×23的栅格阵列,它具有最大深度为3,可能层次分别为0,1,2,3。其中:
第0层边长上的最大栅格数为23-0=8;
第1层边长上的最大栅格数为23-1=4;
第2层边长上的最大栅格数为23-2=2;
第3层边长上的最大栅格数为23-3=1。当栅格阵列为非2N·2N时,为了便于进行四叉树编码可适当增加一部分零使其满足2N×2N。
常规四叉封所占的内外存空间比较大,因为它不仅要记录每个结点值,还需记录结点的一个前趋结点及四个后继结点,以反映结点之间联系。对栅格数据进行运算时,还要作遍历树结点的运算。这样,增加了操作的复杂性。所以实际上,在地理信息系统或图象分割中不采用常规四叉树,而用线性四叉树(Linear Quadtree)。
二、线性四叉树
从数据结构角度看,树数据结构本身属于非线性数据结构。这里所说的线性四叉树编码是指用四叉树的方式组织数据,但并不以四叉树方式存储数据。也就是说,它不像常规四叉树那样存储树中各个结点及其相互间关系,而是通过编码四叉树的叶结点来表示数据块的层次和空间关系。所说的叶结点都具有一个反映位置的关键字,亦称位置码,以此表示它所处位置。其实质是把原来大小相等的栅格集合转变成大小不等的正方形集合,并对不同尺寸和位置的正方形集合赋予一个位置码。
图3-15(a)显示的栅格数据图,其中属性值为1,背景值为0。该图的线性四叉封表示可通过19个叶结点来描述。图中叶结点(1)到(19)分别表示不同尺寸的正方形集合。所以,线性四叉树的关键是如何对叶结点进行编码,通常说的各种四叉树编码法的差异,主要在于表示位置码的编码方法不同。
三、线性四叉树的编码
讨论对线性四叉树编码之前,首先讨论一下四叉树编码中采用的自上而下分割以及自下而上的合并过程。设一个n×n的栅格阵列(n=2k,k>1)对其进行自上而下分割过程,可如下用四进制码说明之。
第一次分割得第一层,这里用P0,P1,P2,P3表示如下:

第二次分割得第二层,这里用P00,P01,P02,P03,P10,P11,P12,P13,P20,P22,P23;P30,P31,P32,P33表示如下:


以下依此类推。
![]()
右上,左下,右下,即NW,NE,SW,SE部分。
其中位置码的位数决定分割的层数,图形越复杂,分割的层数越多,相应的位置码的位数亦越多。
这种自上而下的分割方法需要大量重复运算,效率比较低,从而出现了自下而上的合并法。
自下而上的合并法,首先根据栅格阵列的行列值转换成最大位数的位置码,然后对上述编码进行排序,依次检查4个相邻位置码的属性值是否相同,若相同将其进行合并,并除去一位最低位置码,这样不断循环直到没有可合并子块为止。这种自下而上合并法,因效率高得以采用。
下面进一步介绍几种线性四叉树的编码。
1.基于深度和层次码的线性四叉树编码。它通过记录叶结点的深度码和层次码来描述叶结点的位置码。
对一幅2N·2N栅格图,具有N层,选用2N位作层次码。
图3-15所示的线性四叉封,其中叶结点(7)的编码为:

该位置码的十进制值为:
20+21+24+25+26+27=243
表3-12表示了图3-15所示的19个叶结点的全部编码值。

2.基于四进制的线性四叉树编码(Mθ)
四叉树的“四等分”概念,从数据结构的角度看很适合用四进制来表示。
例如:一幅2N×2N的图象,用四叉树描述时最多有N层,所以可用N位四进制数表示所有位置码。图3-15的23×23栅格图中,叶结点(7)的编码可表示为:

下面以自下而上方法,说明四进制编码过程。首先将栅格阵列的行
![]()
![]()
列的Mθ码为Mθ=2×1+101=103;二进制第111行,第111列的Mθ码为Mθ=2·111+111=333。

反之,已知四叉树四进制编码值,也可求二进制行列值。其算法为,首先明确Mθ码对行,列方向的贡献,归纳如下:


这样,如果已知Mθ码为103,则二进制行列值如下:

这表示Mθ码为103单元处于第1行第5列,同样如果已知Mθ码为333,则其二进制行列值为:

这表示Mθ码为333的单元,处于第7行第7列。
利用上述方法,对每个栅格进行编码得图3-16(a)编码表。然后将编码值排序,检查相邻4个码的属性值,如相同,进行合并,除去最低位。例如图3-16(a)中,000,001,002,003相邻四位码具有相同属性值,为此进行合并,其编码值改成为00。以此类推,这样经过一次全检测后,再检测上层的相邻四个块编码的属性值,如相同再合并。如此循环直到没有能够合并的子块为止,最后得图3-16(b)。
这种编码的优点是便于实现行列值及编码值之间的转换。由于栅格数据结构中的数据通常用二维矩阵来表示,实现这种转换,便于对四叉树的操作。
这种编码的缺点是存储器开销大,加上一般软件都不支持四进制码,通常要用十进制码来表示每位四进制码。显然这样既浪费了存储空间,也影响运算效率。从而出现了基于十进制的线性四叉封编码。
3.基于十进制的线性四叉树编码(MD码)
这种编码方法的建立过程类似于前面的基于四进制的线性四叉树编码。
图3-15的线性四叉树的十进制编码如图3-17(a)所示,经自下而上归并得图3-17(b)。
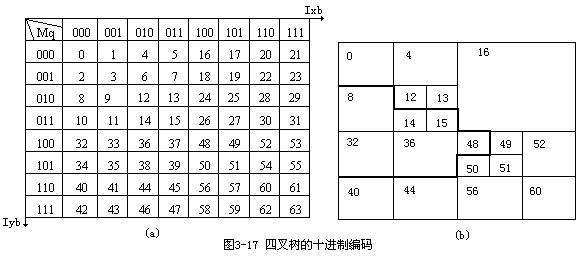
归并时,首先将图3-17(a)中码进行排序,依次检查四个相邻叶结点的属性代码是否相同,若相同归并成一个父结点,记下地址及代码,否则不予归并。然后,再归并更高一层的父结点,如此循环,直到最后。
同基于四进制的线性四叉树编码一样,十进制四叉树编码其栅格阵列的行列号之间可方便地进行转换。
已知栅格阵列的行列号转换成四叉树的十进制码的方法,如上所述,首先将栅格阵列的行列号,分别以二进制形式表示,得到二进制的行号
![]()
到四叉树叶结点的二进制地址码,进而将二进制码转成十进制码得四叉树的十进制编码MD。
例如求图3-17(a)中第3(011)行,第2(010)列所对应的MD码为:

同样,已知MD码,可将其转换成二进制码,然后,隔位抽取便可得到相应的二进制行号,列号,这就是MD码在栅格阵列中所处的行列位置。
四叉树的十进制编码不仅比四进制编码节省存储空间,而且,前后两个MD码之间差即代表了叶结点的大小,从而还可进一步利用游程编码对数据进行压缩。图3-17所示栅格数据的线性四叉树的十进制编码可归纳成表3-13(a),并进一步用二维游程编码如表3-13(b)所示。

总之,四叉树编码有许多优点,首先是它具有可变分辨率,它能够按图形特征、自动调整分割尺寸和层次,既能精确表示图形的细节部分,又可以根据图形结构除去不必要存储量,所以这样编码效率高;其次,四叉树编码具有区域性质,适合于图形图象的分析运算;另外,四叉树编码便于岛的分析,便于同栅格矩阵之间进行转换。因此越来越受到地理信息系统工作人员的关注。
应该指出,上面的数据编码针对的均是二维空间信息。在实际中,许多问题要求地理信息系统能处理三维的空间信息。例如,研究矿藏资源地下分布情况、研究不同深度层土壤肥力情况等,只用二维方法来描述是不够的,因为它们都涉及三维信息,从而出现了三维地理信息系统。